


![大数据平台数据管控解决方案[47页PPT]-文库](https://wenku-1307431297.cos.ap-shanghai.myqcloud.com/大数据平台数据管控解决方案[47页PPT]-82919ab2c9-pptx-1.webp)
大数据平台数据管控解决方案[47页PPT]
数据管控系统实施目标数据管控系统实施是为解决企业所面临的数据标准问题、数据质量问题、元数据管理问题。数据标准规范落地推动数据标准在全企业的执行落地,规范化管理构成数据平台的业务和技...

数据标准管理实践白皮书
《数据标准管理实践白皮书》国家开发银行:钟晓南方电网有限责任公司:陈彬中国移动浙江公司:傅一平中国外运股份有限公司:宋清波国家能源集团信息公司:牟岩中国电信集团有限公司企业信息化部...

数据要素白皮书2023版
前言2022年12月,中共中央、国务院印发《关于构建数据基础制度更好发挥数据要素作用的意见》(下称“数据二十条”),这是我国首部从生产要素高度系统部署数据要素价值释放的国家级专项政策文件...

探寻绿色经济与数字经济的交集32页
平安证券策略策略深度报告正文目录一、引言:探寻绿色经济与数字经济的交集.51.1数字经济能够促进绿色经济目标的达成51.2绿色经济帮助数字经济实现可持续发展..61.3框架:数字化的碳中和路径与...

数据中心全生命周期绿色算力指数白皮书-远景科技-2024-6
数据中心全生命周期绿色算力指数白皮书指导单位:河北省数据和政务服务局、河北省发展和改革委员会、河北省能源局、张家口市人民政府参编单位:安永(中国)企业咨询有限公司、北京抖音信息服务...
-28a0fb9fae-pdf-1.webp)
数据资产管理白皮书(2024)
袋鼠云数据资产管理白皮书编制说明近年来,政府将数据要素纳入了经济发展的重要指示性文件当中,希望利用数据驱动,让数据产生价值.2023年8月21日,财政部正式对外发布《企业数据资源相关会计处...

2021智慧医院创新白皮书
B动脉网蛋壳研究院vcbeat.topVCBeat ResearchBOEKEYPOINT核心观点1.智慧医院是未来医疗健康生活的必选项●医疗机构智慧化升级有利于改善患者就医体验医院智慧化实现了诊前咨询预约、诊中流程优...
![[2023版]医院云服务应用状况调查报告-文库](https://wenku-1307431297.cos.ap-shanghai.myqcloud.com/[2023版]医院云服务应用状况调查报告-d58e648118-pdf-1.webp)
[2023版]医院云服务应用状况调查报告
医院云服务应用状况调查报告目录一、概述..二、主要发现和问题分析…2.1调查主要发现…….72.1.1使用率与医院级别正相关….72.1.2使用率与医院规模正相关.....82.1.3使用率与信息化水平正相关…...
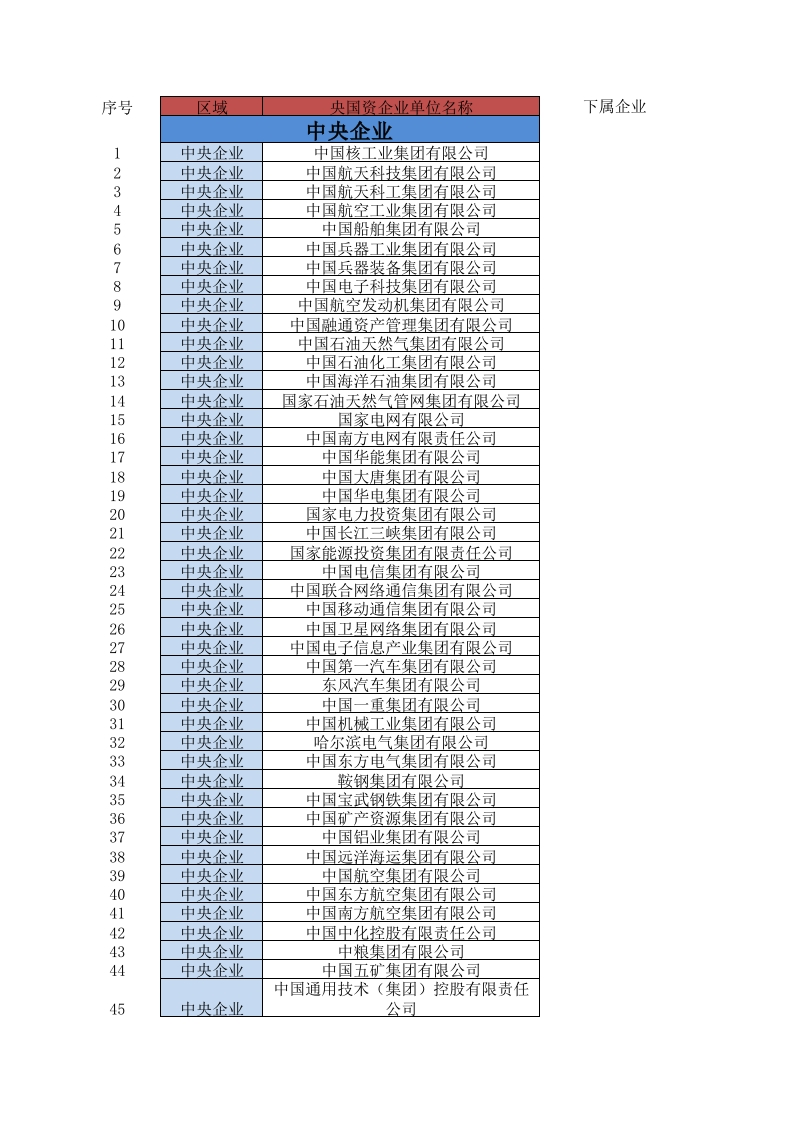
98家央企和30个省国有企业名单
93中央企业华侨城集团有限公司94中央企业南光(集团)有限公司[中国南光集团有限公司]95中央企业中国电气装备集团有限公司中央企业中国物流集团有限公司9中央企业中国国新控股有限责任公司中央...
