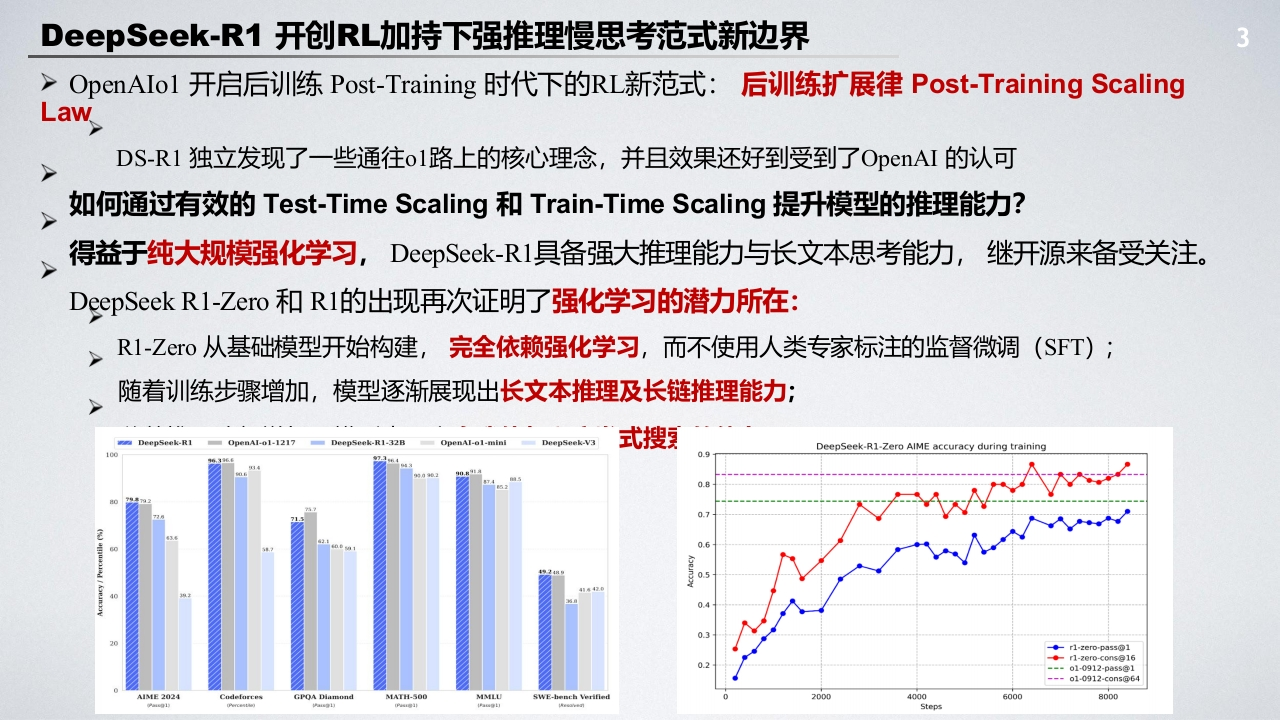
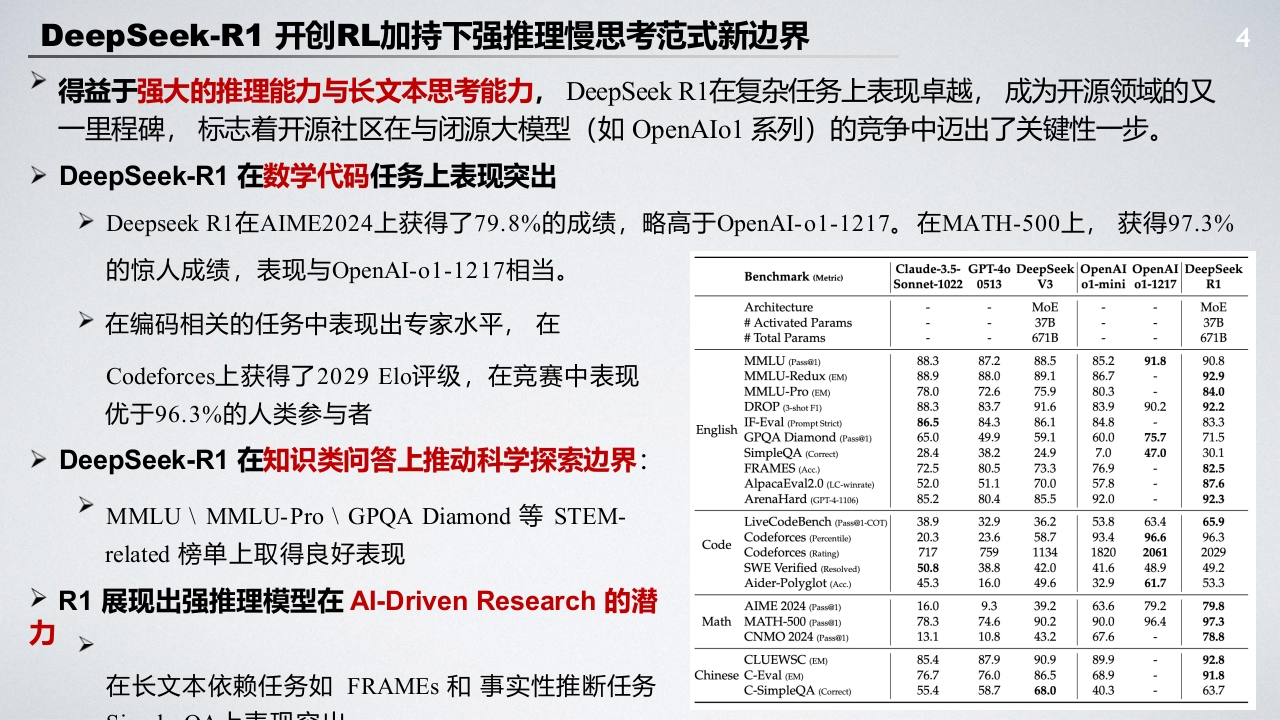
DeepSeek-R1开创RL加持下强推理慢思考范式新边界3>OpenAIo1开启后训练Post-Training时代下的RL新范式:后训练扩展律Post-Training ScalingLawDS-R1独立发现了一些通往ol路上的核心理念,并且效果还好到受到了OpenAI的认可如何通过有效的Test-Time Scaling和Train-Time Scaling提升模型的推理能力?人得益于纯大规模强化学习,DeepSeek-Rl具备强大推理能力与长文本思考能力,继开源来备受关注。DeepSeek R1-Zero和R1的出现再次证明了强化学习的潜力所在:R1-Zro从基础模型开始构建,完全依赖强化学习,而不使用人类专家标注的监督微调(SFT);随着训练步骤增加,模型逐渐展现出长文本推理及长链推理能力;DeepSeek-R0pnA1-01-121-R1-32BpenAl-ol-minDeepSeek-V3式搜DeepSeek-R1-Zero AIME accuracy during training◆-r1-zero-p3s5@1◆r1-zer0-c0nsg16---o1-0912-pa55@1--o1-0912-c0ns@64MATH20004060008000Step




2023-c0b66542e1-pdf-1.webp)
-9f7cebbfbc-pdf-1.webp)

-8d4d068c68-pdf-1.webp)
-92e9466b0b-pdf-1.webp)
-f97dfadece-pdf-1.webp)

![智慧校园建设方案[179页Word]-文库](https://wenku-1307431297.cos.ap-shanghai.myqcloud.com/智慧校园建设方案[179页Word]-9ee1710f34-docx-1.webp)


-c2ae98233e-pdf-1.webp)


暂无评论内容