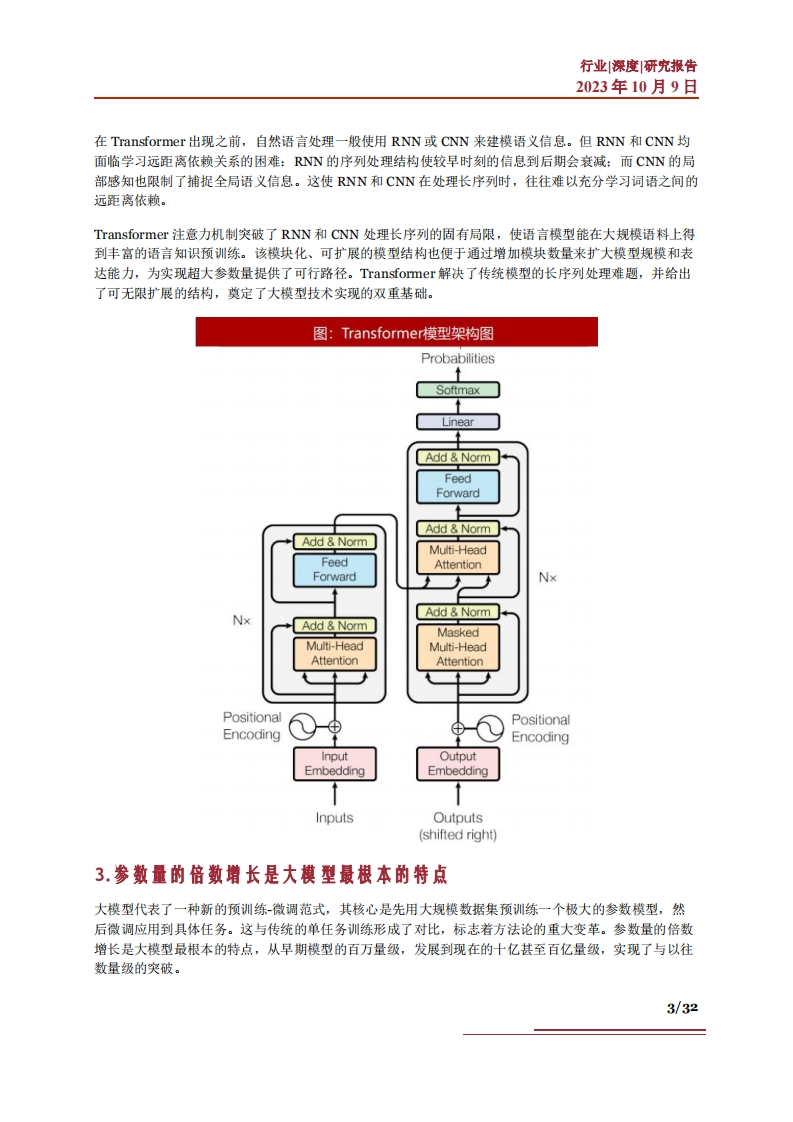
行业深度研究报告2023年10月9日在Transformer出现之前,自然语言处理一般使用RNN或CNN来建模语义信息。但RNN和CNN均面临学习远距离依赖关系的困难:RNN的序列处理结构使较早时刻的信息到后期会衰减:而CNN的局部感知也限制了捕捉全局语义信息。这使RNN和CNN在处理长序列时,往往难以充分学习词语之间的远距离依赖。Transformer注意力机制突破了RNN和CNN处理长序列的固有局限,使语言模型能在大规模语料上得到丰富的语言知识预训练。该模块化、可扩展的模型结构也便于通过增加模块数量来扩大模型规模和表达能力,为实现超大参数量提供了可行路径。Transformer解决了传统模型的长序列处理难题,并给出了可无限扩展的结构,奠定了大模型技术实现的双重基础。图:Transformer模型架构图ProbabilitiesSoftmaxLinearAdd NormFeedForwardAdd NormAdd NormMulti-HeadFeedAttentionForwardNxAdd NormNxAdd NormMaskedMulti-HeadMulti-HeadAttentionAttentionPositionalPositionalEncodingEncodingInputOutputEmbeddingEmbeddingInputsOutputs(shifted right)3.参数量的倍数增长是大模型最根本的特点大模型代表了一种新的预训练-微调范式,其核心是先用大规模数据集预训练一个极大的参数模型,然后微调应用到具体任务。这与传统的单任务训练形成了对比,标志若方法论的重大变革。参数量的倍数增长是大模型最根本的特点,从早期模型的百万量级,发展到现在的十亿甚至百亿量级,实现了与以往数量级的突破。3/32





2023-c0b66542e1-pdf-1.webp)
-9f7cebbfbc-pdf-1.webp)

-8d4d068c68-pdf-1.webp)
-92e9466b0b-pdf-1.webp)
-f97dfadece-pdf-1.webp)
-2b3cd5c63c-docx-1.webp)


暂无评论内容