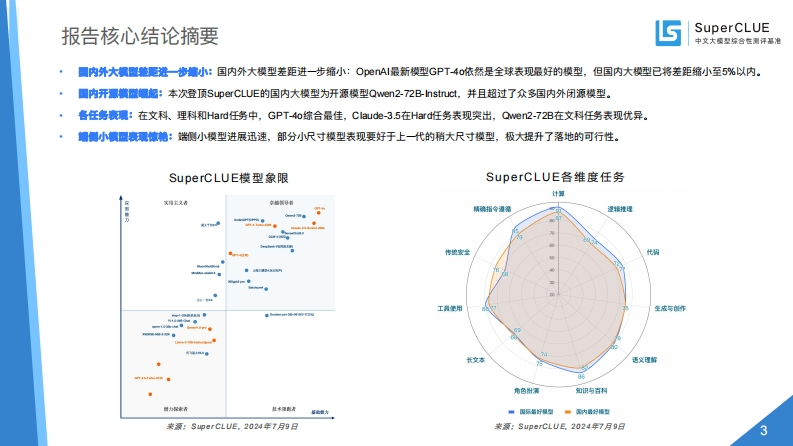
报告核心结论摘要SuperCLUE中文大候型综合性测评基准■内外大型进一小:国内外大模型差距进一步缩小:Op阳41最新模型GPT4o依然是全球表现最好的模型,但国内大模型已将差距缩小至5%以内。■内开世量起:本次登顶SuperCLUE的国内大模型为开源模型Qwen2-72B-nhst机uc,并且超过了众多国内外闭源模型。售任毒囊:在文科、理科和Hard任务中,GPT-4o综合最佳,Claude-3.5在Hard任务表现突出,Qwen2-72B在文科任务表现优异。侧小、回算槽:诺侧小模型进展迅速,部分小尺寸模型表现要好于上一代的稍大尺寸模型,极大提升了落地的可行性。SuperCLUE模型象限SuperCLUE各维度任务计算实宝之者精确指伞酒福推理传快安全代钢工具使用生应与创作74长文本适义理解86角色周演知识与百利细国板结好根型=黑内最好楼型来源:SuperCLUE.2024年7月9日来源:Sup8 CLUE,2024年7月9日3





2023-c0b66542e1-pdf-1.webp)
-9f7cebbfbc-pdf-1.webp)

-8d4d068c68-pdf-1.webp)
-92e9466b0b-pdf-1.webp)
-f97dfadece-pdf-1.webp)
-2b3cd5c63c-docx-1.webp)


暂无评论内容