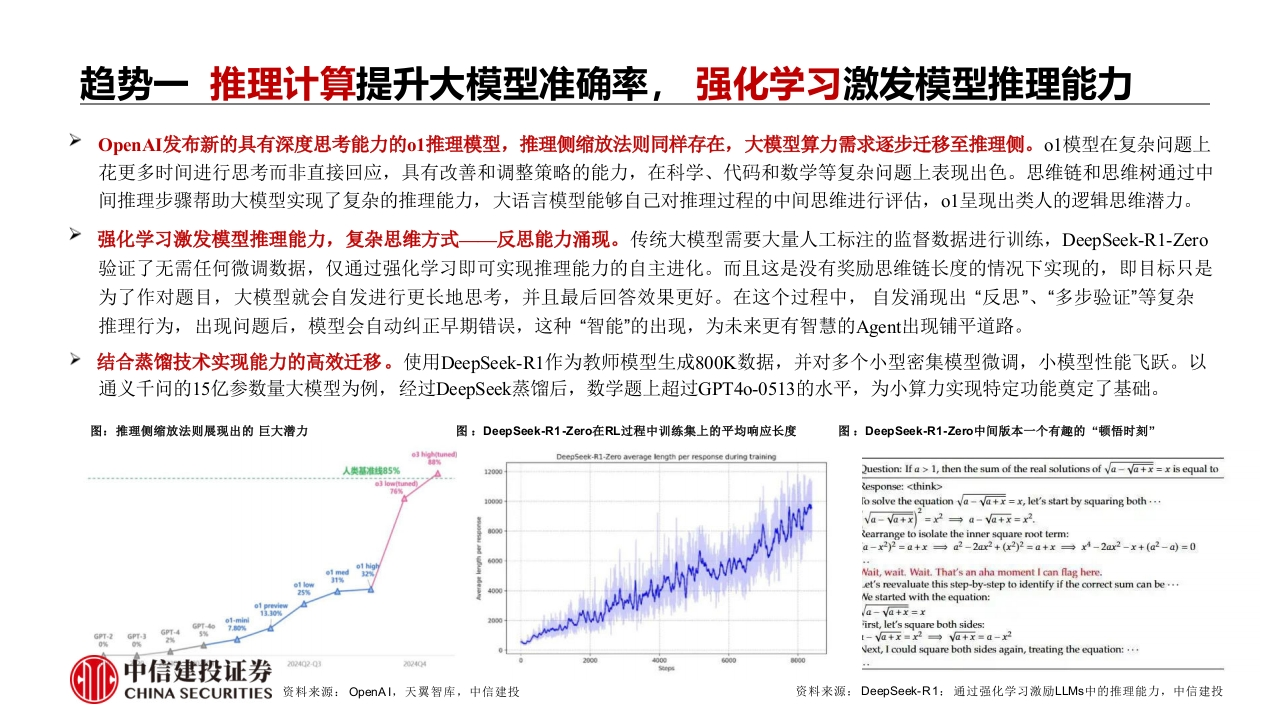
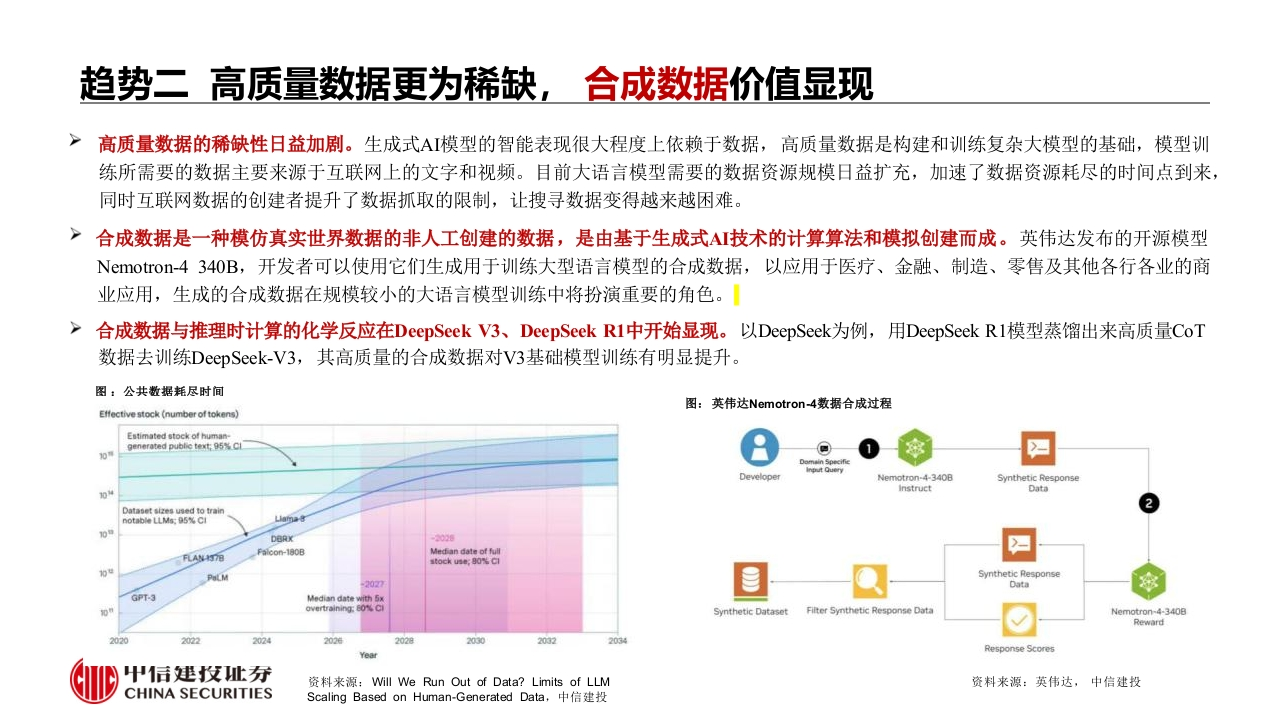
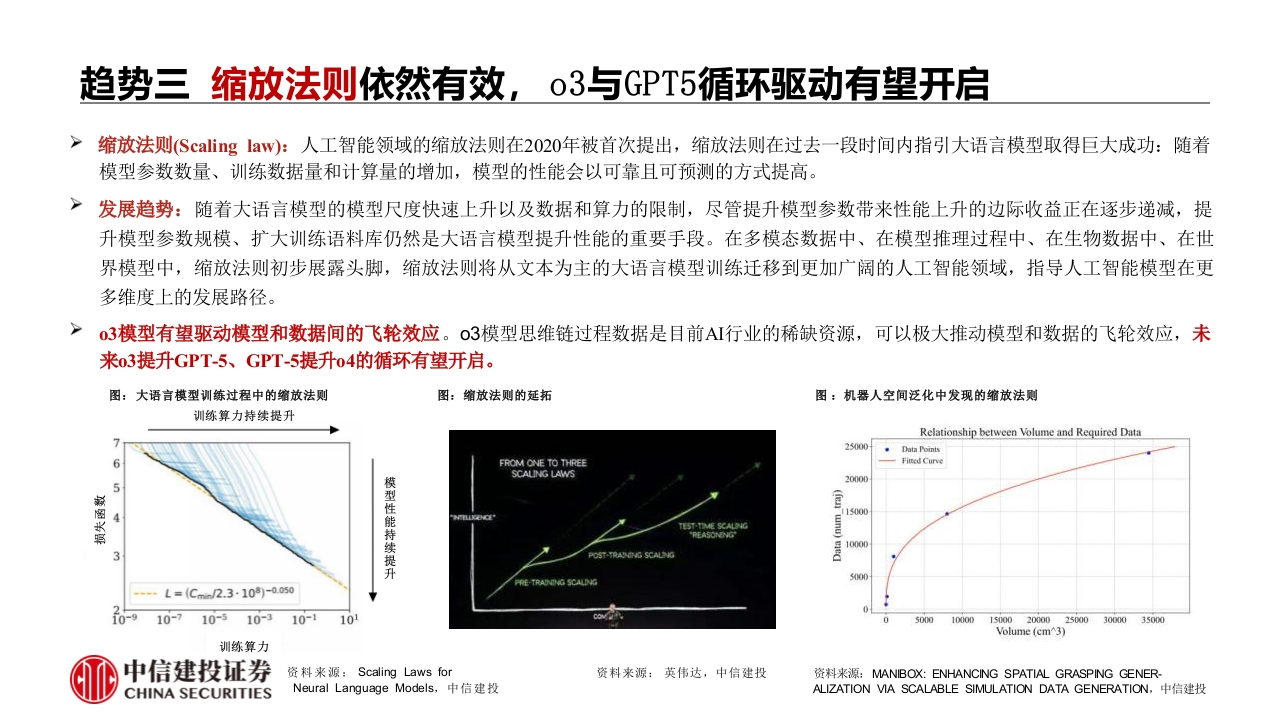
趋势一推理计算提升大摸型准确率,强化学习激发模型推理能力OpAI发布新的具有深度思考能力的o1推理模型,推理侧缩放法则同样存在,大模型算力需求逐步迁移至推理侧。o1模型在复杂问题上花更多时间进行思考而非直接回应,具有改善和调整策略的能力,在科学、代码和数学等复杂问题上表现出色。思维链和思维树通过中间推理步骤帮助大模型实现了复杂的推理能力,大语言模型能够自己对推理过程的中间思维进行评估,O1呈现出类人的逻辑思维潜力。强化学习激发模型推理能力,复杂思维方式一反思能力涌现。传统大模型需要大量人工标注的监督数据进行训练,DeepSeek-Rl-Zero验证了无需任何微调数据,仅通过强化学习即可实现推理能力的自主进化。而且这是没有奖励思维链长度的情况下实现的,即目标只是为了作对题目,大模型就会自发进行更长地思考,并且最后回答效果更好。在这个过程中,自发涌现出“反思”、“多步验证”等复杂推理行为,出现问题后,模型会自动纠正早期错误,这种“智能"的出现,为未来更有智慧的Agt出现铺平道路。结合蒸馏技术实现能力的高效迁移。使用DeepSeek-R1作为教师模型生成800K数据,并对多个小型密集模型微调,小模型性能飞跃。以通义千问的15亿参数量大模型为例,经过DeepSeek蒸馏后,数学题上超过GPT4o-0513的水平,为小算力实现特定功能奠定了基础。图:推理侧缩放法则展现出的巨大潜力图:DeepSeek-R1Zero在RL过程中训练集上的平均响应长度图:DeepSeek-R1-Zero中间版本一个有趣的“顿悟时刻”Deegseek-R1-Zero average length per response during training人类准线859Question:If a 1,then the sum of the real solutions of a-va+=x is equal toResponse:fo solve the equation va-va+x=x,let's start by squaring both..a-a+x=x2→a-a+x=x2.Rearrange to isolate the inner square root term:a-x22=a+x=a2-2ur2+(x22=a+x→x4-2ar2-x+(a2-ad=0Wait,wait.Wait.That's an aha moment I can flag here.et's reevaluate this step-by-step to identify if the correct sum can be...Ne started with the equation:a-va+x=xirst,let's square both sides:t-Va+x=x2→Va+x=a-x2Next,I could square both sides again,treating the equation:...中信建投证券202404CHINA SECURITIES资料来源:OpenAI,天翼智库,中信建投资料来源:DeepSeek-R1:通过强化学习激励LLMs中的推理能力,中信建投



2023-c0b66542e1-pdf-1.webp)
-9f7cebbfbc-pdf-1.webp)

-8d4d068c68-pdf-1.webp)
-92e9466b0b-pdf-1.webp)
-f97dfadece-pdf-1.webp)
-2b3cd5c63c-docx-1.webp)


暂无评论内容