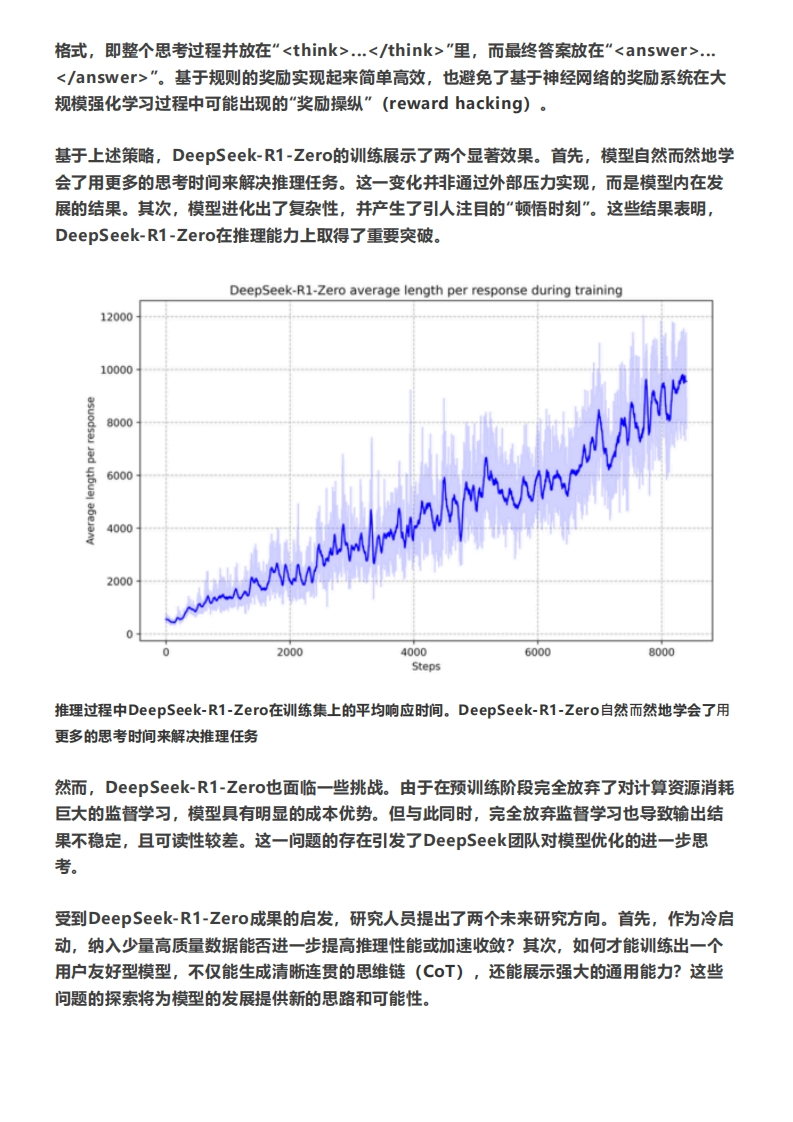
1.背景1该模型的开发背景源于传统语言模型在复杂推理任务中的局限性,尤其是在需要多步逻辑推理的场景中。尽管现有的语言模型在生成文本和理解语言方面表现出色,但在数学推理、代码生成等需要精确逻辑推理的任务中,表现仍然有限。为了解决这一问题,DeepSeek团队提出了基于强化学习的训练方法,开发了DeepSeekR1系列模型。该模型的核心目标是通过强化学习和大规模训练,提升模型在复杂推理任务中的表现。DeepSeek-R1-Zero是这一系列中的第一个模型,它通过纯强化学习训练,无需监督微调(SFT),展现出强大的推理能力。然而,DeepSeek-R1-Zero在训练过程中也暴露出一些问题,如可读性差、语言混合等。为了进一步优化模型,DeepSeek团队引入了冷启动数据和多阶段训练方法,开发了DeepSeek-R1。冷启动数据的使用使得模型在训练初期能够更快地收敛,并且通过多阶段训练,模型的推理能力和可读性得到了显著提升。此外,团队还探索了蒸馏技术,将大型模型的推理能力传递到小型模型,使得小型模型在推理任务中也能表现出色。总的来说,DeepSeek-R1的开发背景是为了解决传统语言模型在复杂推理任务中的不足,通过强化学习和蒸馏技术,提升模型在数学推理、代码生成等任务中的表现,并为研究社区提供开源的推理模型资源。1.1 DeepSeek系列模型2023年7月,国内大型私募基金幻方量化成立了子公司深度求索,他们储备了过万张A100和H800计算显卡,开启了半年迭代一版大模型的探索历程:·2024年1月,深度求索发布了第一代模型,DeepSeekMoE系列,最大的版本有67B参数,确立了混合专家模型(Mo)架构路线,能大幅减少训练和生成期间的成本。另外,DeepSeekMoE发现了细粒度多数量Expert模块以及设立独立的共享Expert模块能获得更加稳定且更好的效果。·2024年5月,深度求索发布了第二代模型,DeepSeek-v2,最大的版本有273B参数。其中最重要的创新是多头潜在注意力机制(Multi-head Latent Attention,MLA)。MLA能大幅降低模型在生成(推理)阶段的显卡缓存占用,据报告可降到原先的5%-13%,因而可以大大提高其在生成阶段的效率。这一创新,配合其他创新使得DeepSeek-v2的生成文字的成本降到只有每百万token一块钱。·2024年12月,深度求索发布了第三代模型,DeepSeek-v3,最大的版本有671B参数。v3采用了多token预测训练(Multi-Token Prediction,MTP)技术以及无损负





2023-c0b66542e1-pdf-1.webp)
-9f7cebbfbc-pdf-1.webp)

-8d4d068c68-pdf-1.webp)
-92e9466b0b-pdf-1.webp)
-f97dfadece-pdf-1.webp)
-2b3cd5c63c-docx-1.webp)


暂无评论内容