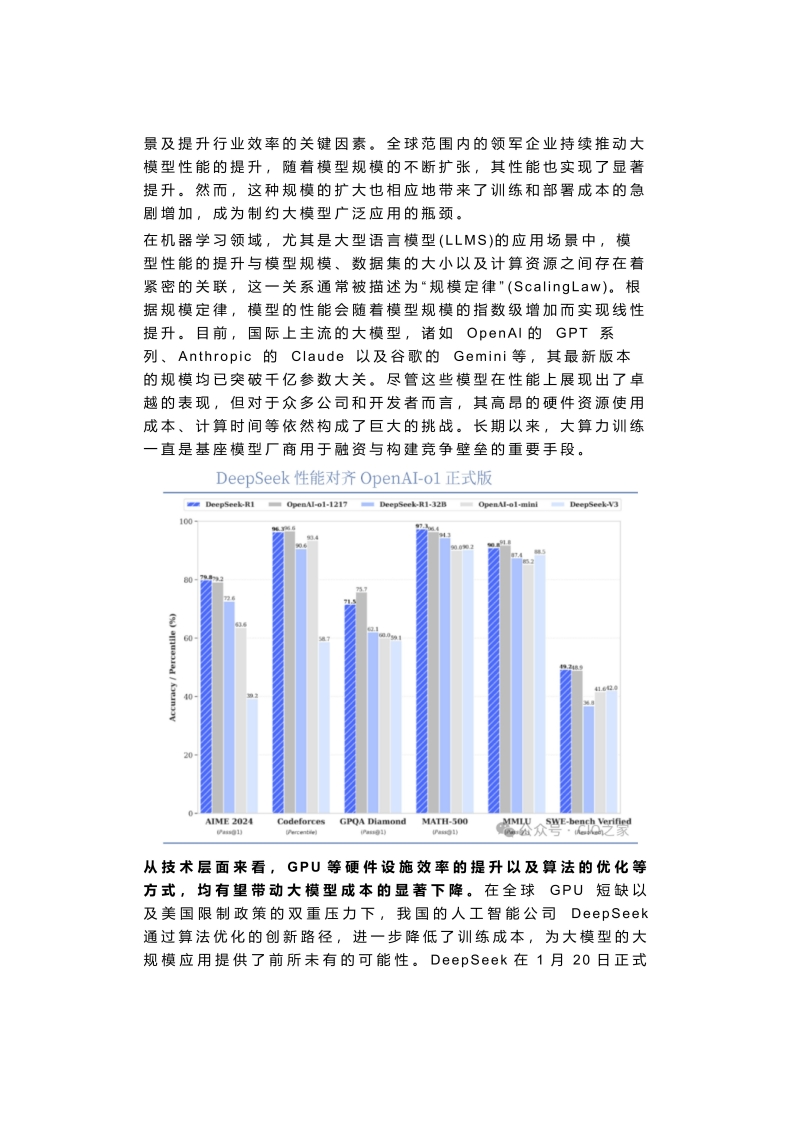
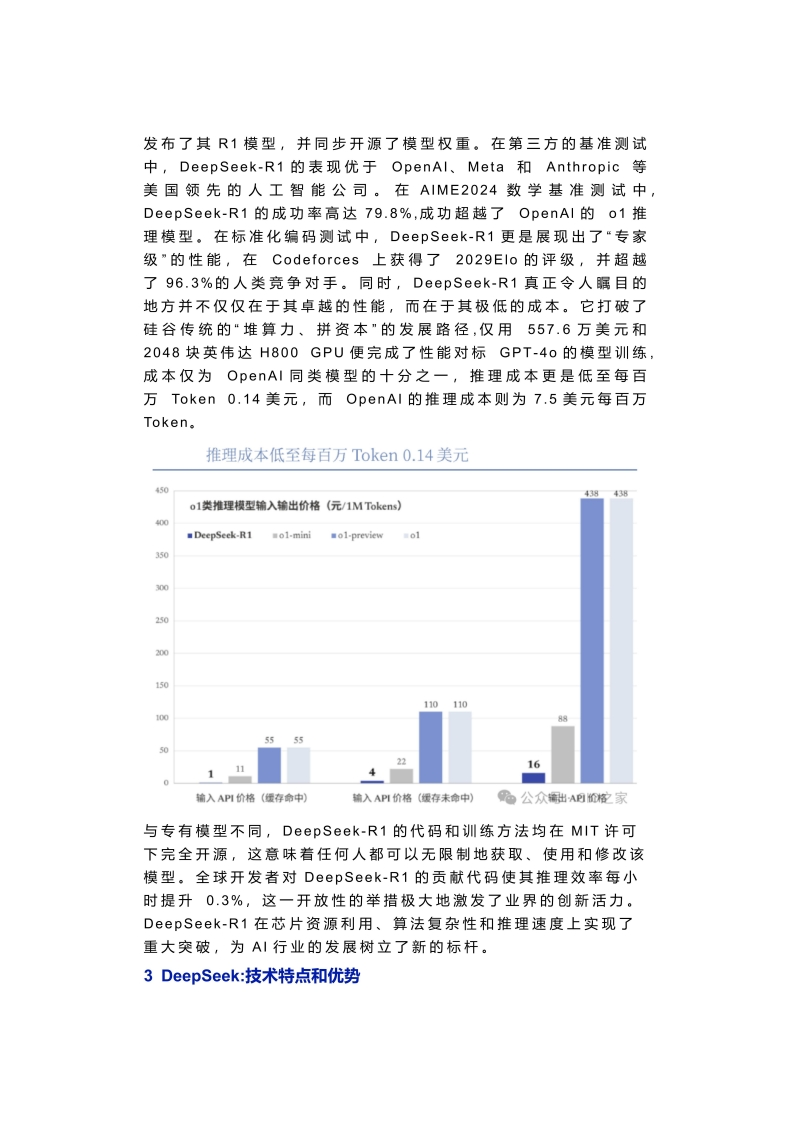
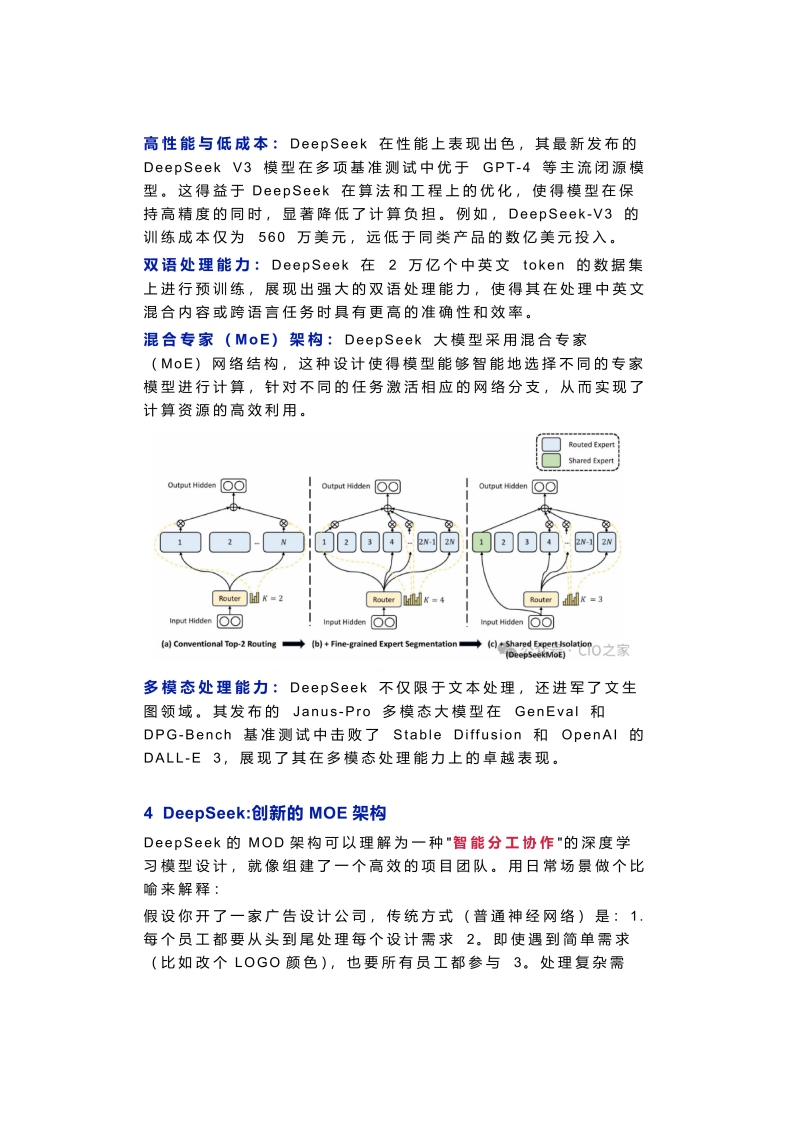
景及提升行业效率的关键因素。全球范围内的领军企业持续推动大模型性能的提升,随着模型规模的不断扩张,其性能也实现了显著提升。然而,这种规模的扩大也相应地带来了训练和部署成本的急剧增加,成为制约大模型广泛应用的瓶颈。在机器学习领域,尤其是大型语言模型(LLMS)的应用场景中,模型性能的提升与模型规模、数据集的大小以及计算资源之间存在着紧密的关联,这一关系通常被描述为“规模定律"(ScalingLaw)。根据规模定律,模型的性能会随着模型规模的指数级增加而实现线性提升。目前,国际上主流的大模型,诸如OpenAl的GPT系列、Anthropic的Claude以及谷歌的Gemini等,其最新版本的规模均已突破干亿参数大关。尽管这些模型在性能上展现出了卓越的表现,但对于众多公司和开发者而言,其高昂的硬件资源使用成本、计算时间等依然构成了巨大的挑战。长期以来,大算力训练一直是基座模型厂商用于融资与构建竞争壁垒的重要手段。DeepSeek性能对齐OpenAI-ol正式版m DeepSeek-RI OpenAl-01-1217 DeepSeek-R1-32BOpenAl-ol-miniDeepSeek-V31006016AIME 2024CodeforcesGPQA DiamondMATH-50001小wrcentie时行0as诗I)从技术层面来看,GPU等硬件设施效率的提升以及算法的优化等方式,均有望带动大模型成本的显著下降。在全球GPU短缺以及美国限制政策的双重压力下,我国的人工智能公司DeepSeek通过算法优化的创新路径,进一步降低了训练成本,为大模型的大规模应用提供了前所未有的可能性。DeepSeek在1月20日正式



2023-c0b66542e1-pdf-1.webp)
-9f7cebbfbc-pdf-1.webp)

-8d4d068c68-pdf-1.webp)
-92e9466b0b-pdf-1.webp)
-f97dfadece-pdf-1.webp)
-2b3cd5c63c-docx-1.webp)


暂无评论内容